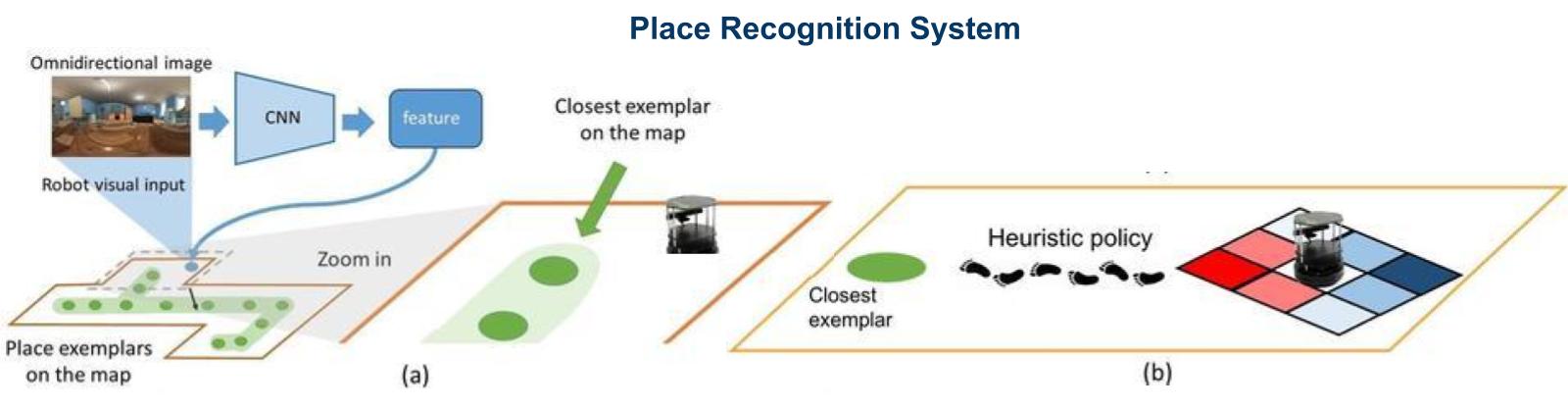
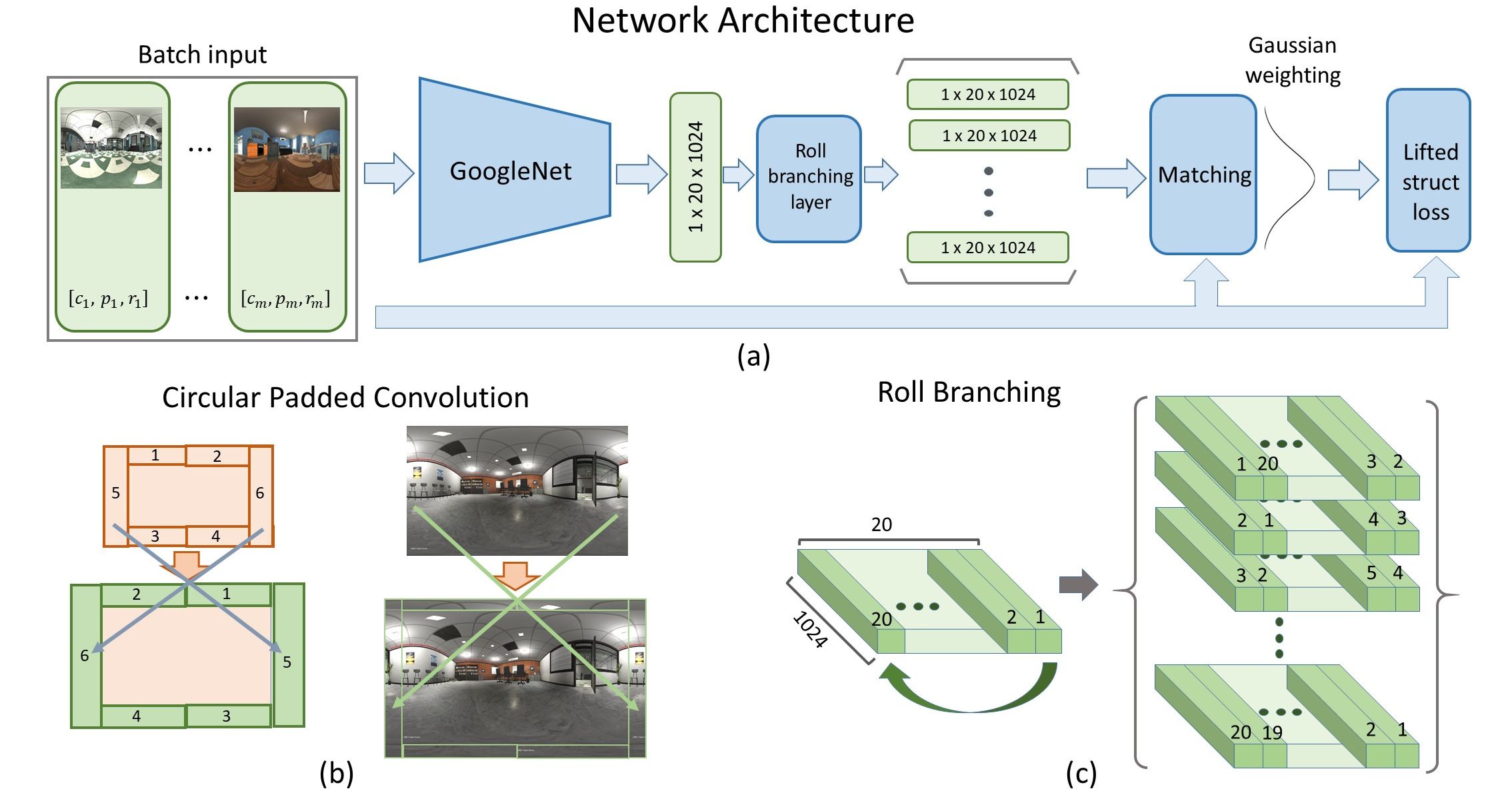
In this video, our approach will be illustrated in animation, and some experimental results, including qualitative and quantative results, will be shown. Besides, the virtual environments where we collected data and samples of our dataset can be seen in the video.
Bibilographic information for this work:
T.H. Wang*, H.J. Huang*, J.T. Lin, C.W. Hu, K.H. Zeng, and M Sun. "Omnidirectional CNN for Visual Place Recognition and Navigation." IEEE International Conference on Robotics and Automation (ICRA), 2018. [Arxiv Preprint][Code]
@article{wang2018omnidirectional,
title={Omnidirectional CNN for Visual Place Recognition and Navigation},
author={Wang, Tsun-Hsuan and Huang, Hung-Jui and Lin, Juan-Ting and Hu, Chan-Wei and Zeng, Kuo-Hao and Sun, Min},
journal={arXiv preprint arXiv:1803.04228},
year={2018}
}
![]()
![]()